kubelet-1-arch
导读
Kubernetes 目前已经成为云原生基础设施和容器编排的事实标准,工程师可以借助 Kubernetes 的标准抽象API,像使用操作系统一样来控制基础设施资源,从而实现基础设施即代码。但是大部分应用开发者可能并不了解 Kubernetes 的数据面即 Kubelet,本文会从Kubernetes系统设计、Kubelet系统框架、Kubelet数据流、CNI/CSI/CRI 来介绍Kubelet。本文并不会出现代码阅读,AI时代,详细的代码阅读找Copilot即可。熟悉Kubelet,有助于我们对Kubernetes的应用有更加清楚的认识,并且更好的进行故障排查。
Kubernetes 系统设计
下图是Kubernetes的核心的组件示意图,这里主要突出控制面和数据面的循环控制逻辑。
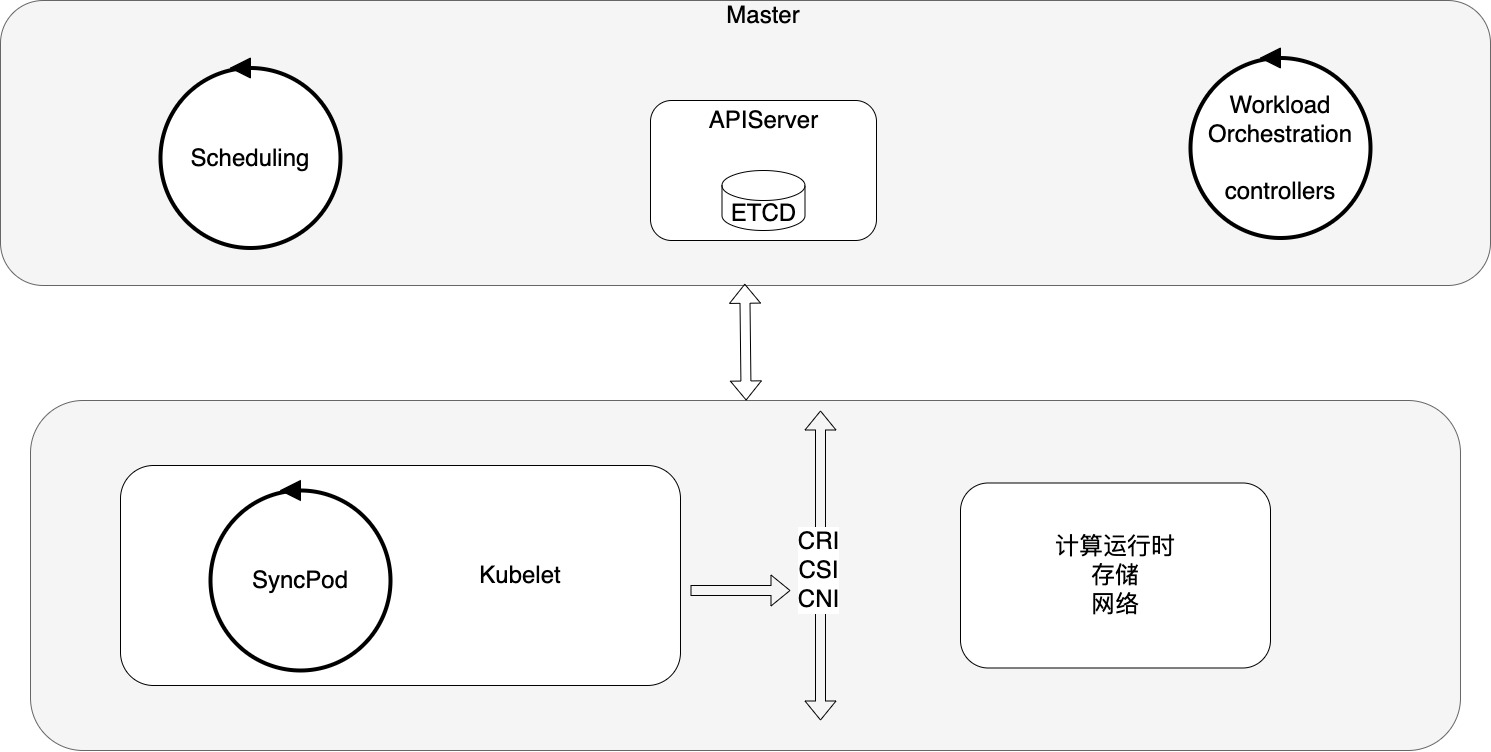
在Kubernetes中,无论是在 Master(控制管理面) 还是在 Minion(数据面Kubelet),其内部都有大量的循环流程,这些循环模式就是 Kubernetes 声明式API的实现方式;
最终一致性
Kubernetes 采用的是最终一致性来保证数据的一致,要达到 Yaml中描述的状态,Kubernetes会不断的观测Pod的实际状态来做出调整,一次Pod创建并不是失败返回不做处理了,而是失败后重试,如果出现异常,那么将会不停的重试,直到依赖的服务恢复。
如果一直有模块出问题,就会一直处于不一致状态。这就对基础设施服务的可用性有相当高的要求,因为 Kubernetes 假设一定能通过幂等重试再次恢复到想要的状态,一旦Kubernetes依赖的底层基础设施在很长一段时间无法恢复甚至是出现一些Bug,那么 Kubernetes 中的Pod 可能也无法恢复,甚至是永远也无法恢复,这就对Pod依赖的基础设施服务有相当高的要求,试想,如果CRI、CNI、CSI 任何组件的可用性和稳定性存在问题,那么Pod出现故障的概率将非常高。做好 IaaS 中网络、存储、计算服务的管理运营,实际上才能更好的使用 Kubernetes。
Google作为搜索领域的鼻祖,用分布式集群的思想解决了数据量大和处理速度慢的问题,但是代价就是廉价服务器故障率太高。 这就要求分布式系统中,程序设计必须要保证容错,能够容忍这些故障;既然故障无法避免,那么就必须从软件层面上,设计出健壮的系统。
如果一个机器宕机,唯一的方式就是在另一台机器上启动同样的服务进程,而让整个系统不受影响;Kubernetes 就是用来解决这些共性问题而设计的系统,我认为这是Kubernetes战胜Mesos和Swarm的根本原因,这里的关键并不在于容器,而是因为它设计出来的一套高度抽象和可扩展的API,让分布式系统的运维、部署、弹性、容灾等变得非常容易。
Kubernetes设计和操作系统其实是异曲同工,成为了多云上的新标准和新界面,让基于Kubernetes开发的云原生应用能够不做代码改造也可以灵活在各大云厂商迁移。
建议大家可以读一下 Kubernetes 联合创始人 Brendan Burns 的书《Design patterns for container-based distributed systems》,该书图文并茂、深入浅出的阐述了其设计思想。
事件驱动的异步系统
Kubernetes 采用基于事件驱动的异步系统,虽然能够大大提高吞吐量和性能,在复杂系统中,各个组件各司其职,通过事件消息驱动,最终达到一个稳态,但是当事件变得非常多的时候,异步的模块之间的消息,也可能让系统产生某些不一致的数据状态问题,排查问题比较困难。
最直接的就是Kubernetes提供了Watch机制,各大组件都是默认通过异步的Watch去实现的;组件内部也是大量的异步过程。
控制循环协调器
下面是官方文档中对于控制循环的描述,它主要运用于机器人和自动化领域,这个模式在Kubernetes中大量存在,这也是大家在看日志的时候发现有大量重复的日志甚至是重复的报错出现的原因,这是很多新人不熟悉 Kubernetes,不知道为啥 Kubernetes 要重复报错的原因,打印一些看起来重复多余的日志的原因。
In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system. In Kubernetes, a controller is a control loop that watches the shared state of the cluster through the API server and makes changes attempting to move the current state towards the desired state. Examples of controllers that ship with Kubernetes today are the replication controller, endpoints controller, namespace controller, and serviceaccounts controller.
为何 Kubernetes 要引入这个设计,我认为主要有三点:
- Google内部近10年来自Borg的生产实践摸索出来基础设施需要声明式模型,声明式的模型可以让基础设施处于无人值守的状态,大幅度提高效率;
- 声明式API的实现,天然的就是需要有程序能够不断的检查,让数据状态达到声明的一致。声明式就是把复杂交给底层,把简单交给用户,相比命令式需要用户去组装成过程,声明式就是把组装过程也交给系统完成,并不是之前的复杂没有了,复杂性并不会消失,而是转移到平台。这一点稍微有经验一点的程序员都知道,程序的代码往往要进行容错处理,比如对请求做循环重试、兜底等操作来让程序的状态可以在一定时间内恢复到正确状态,这就是声明式开发模型的雏形。
- 最终一致性是水平触发(level trigger)而非边缘触发(edge trigger),边缘触发有个问题就是往往需要依赖触发的瞬间去捕获某个事件做状态更新,在分布式系统中,事件是容易丢失的,丢失后状态就错了。最终还是要靠校验机制去做补偿,因此还是需要去做循环校验机制。
八卦一下Kubernetes的联合创始人之一Brendan Burns 博士曾经的研究方向是机器人和自动化,估计对这种控制器模式非常熟悉。
其实这种控制循环模式也存在问题,主要逻辑就在于差异对比的计算过程即协调,在某些场景下的逻辑还是比较复杂的,需要涵盖各种情况,并且Kubernetes的控制循环有一些基本假设需要成立,否则很可能是误判。
第一是 Desired State Of World,也即是Source of truth,你需要弄清楚什么是控制器的Source Of Truth,大部分情况下,他都是我们定义的CRD期望的状态,那么我们直接从Kubernetes去拿这些状态就行,一般很少出现数据不一致或者同步慢,但是有时候其实DSW还包括其他的期望状态,可能并不属于CRD里定义的,这个时候你依赖的可信源是不是真的可信就很难说,很多情况下Source of truth 可能是从某个微服务获取的,如果获取错误或者失败或者不完整,而你把它当做完整的可信源,那就完蛋了,在进行 reconcile的时候,你会把 Actual State Of World 中多余的部分全部删掉或者错误的去更新状态,因此需要协定好SourceOfTruth的状态约定。
第二是 Actual State Of World,因为 ASW 其实主要用来查询真实状态和做更新写入,如果 ASW 是可以幂等更新还好,如果不能幂等更新,那一定要做兜底,不要出现大量的错误更新操作(比如大批量删除、修改),这个往往会造成大量的数据错误,其实这个问题就算是在不用控制循环框架的服务也同样存在。
循环控制器的设计理念在Kubelet中也体现的淋漓尽致。
Kubelet 系统框架
主体框架
Kubelet 是 Kubernetes的计算节点组件,主要负责Pod资源实体相关的管理工作。Kubelet 整体上是通过异步IO select 不断的轮训各个数据源,然后针对不同的数据源以及事件,做出不同的反应; Kubelet 中共监听了五大channel 中的数据,分别是以下channel:
configCh 负责 整合来自 本地、http 和 apiserver的Pod资源变更,根据不同的变更事件,执行不同的处理逻辑;
plegCh pleg 是Kubelet 中的一个事件生成组件,全称是 pod lifecycle event generator ,plegCh 就是用于获取这些事件的通道,主要监听pod内容器状态变化的事件;
syncCh 定时器channel,用于主动触发 Kubelet 的一次循环更新,默认是1s一次;这个同步时间间隔的设置,取决于 Kubelet 上报状态的时间间隔,最好是小于 Kubelet 上报时间间隔;
housekeepingCh: 定时器 channel,用来定期清理Pod和Node资源,包括存储卷,Cgroup等Pod依赖的资源,默认 2s 触发一次;
liveness & readiness 是Pod的容器存活状态管理器的一个channel,主要用于同步Pod的容器存活状态;

上图主要是粗略的画出系统代码的主轮廓,方便大家自行阅读细节;后续我会挑几个组件和流程,让ChatGPT讲解其中的代码(AI时代,使用ChatGPT才是正确高效阅读代码的方式);
Kubelet 数据流图
下面主要说明 Kubelet 这个异步系统里,数据交互流程和控制逻辑的主要框架图,箭头指向表示数据传递给了哪一个组件,不会贴代码里庞大的业务逻辑,这些我会标注代码位置,大家可以自行查看。注意笔者的分析并不是基于最新的Kubernetes代码,而是基于1.11版本的,新版本应该会有所变化,但是基本框架是不变的。
学习开源代码的程序控制逻辑和数据结构布局设计,清楚的知道程序的数据流、控制流都是怎么执行和协作的,有利于学习如何写出健壮的程序,因为数据结构和控制逻辑往往涉及到计算机基础知识,而程序业务逻辑则不然,在阅读源码的时候切记不要一开始都陷入过多的业务细节类代码,否则很容易引起不适,业务细节类代码特别适合在排查问题的时候进行反复查阅。
所以这里主要会说明程序的控制逻辑和数据流,主要涉及的是 Kubelet 如何做 Pod 的增删改查流程和状态同步,这里说明下,并不包含庞大的Kubelet 内部的所有组件,比如 驱逐组件、存储卷管理、Cgroup、镜像GC等相关管理,也不包括CNI、CRI、CSI的具体领域相关的实现部分;
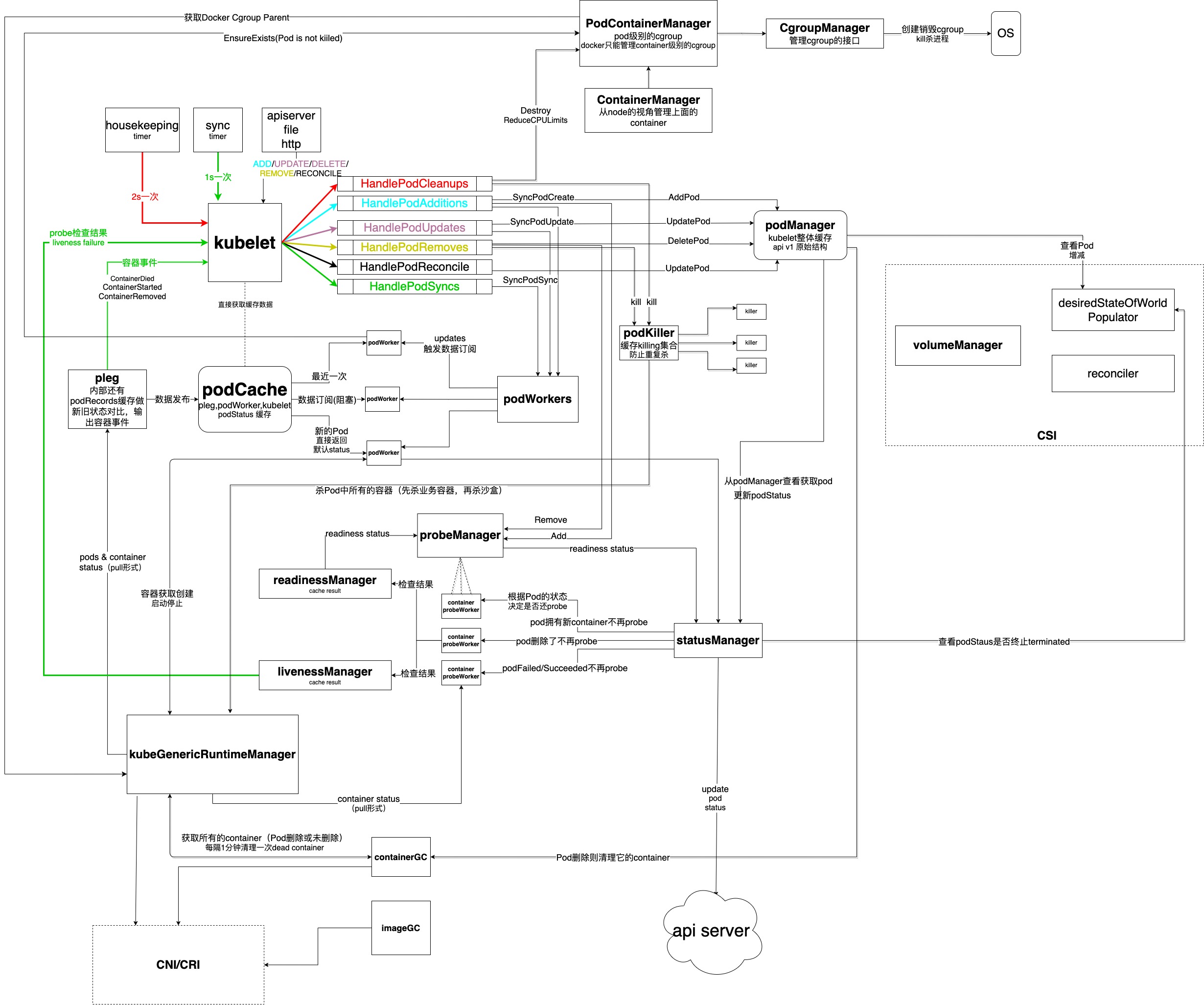
下面简单介绍下Kubelet数据同步管理的几个关键组件:
kubelet main loop,这是 整个 Kubelet 的管理协程,负责从各个渠道监听消息,包括时间驱动和事件驱动的消息;这些源包括housekeeping、timer、apiserver、file、http等podCachepod状态信息缓存服务,负责缓存订阅和发布pleg负责pod状态变化消息投递和缓存更新,是podCache的数据发布者,该模块笔者会单独写文章再来详细说明。podWorker负责管理pod,每个pod都会有一个podWorker负责,它也是podCache的数据订阅者,是pleg的消息消费者podKiller负责统筹接受所有杀pod 的信号,并丢给 killer 协程去执行具体的杀死动作,注意这里并不负责pod被杀后的善后工作,包括数据清理等,善后工作是异步进行的。kubeGenericRuntimeManager是CRI对接管理部分,具体可以看笔者之前的文章kubelet之cri演变史 (opens new window),也成功预测了dockershim会退出Kubernetes的历史舞台。PodContainerManager是Kubelet 保障QoS的关键模块,主要用来做Cgroup 相关配置和操作,该模块笔者会单独写文章来详细说明。probeManager就是Pod里配置Readiness和Liveness部分的具体实现,它通过启动containerProbeWorker来和kubeGenericRuntimeManager交互,将从CRI获取的数据以及对container的服务状态检查结果 放入readinessManager和livenessManager进行缓存。livenessManager还会将liveness消息直接投递给Kubelet大循环,触发一次podWorker的同步。最后其他模块可通过probeManager获取readiness和liveness的数据。此部分在微服务做滚动更新的时候比较重要,该参数的配置决定着工作负载会如何去探测来做到服务的高可用。statusManager负责在Kubelet这里收集pod真实状态的部分,pod的状态最终就是由statusManager负责上报给 apiserver的。syncNodeStatuskubelet 作为节点上的agent,必定需要上报节点相关信息,syncNodeStatus就是负责节点状态信息的定期上报和初始化的,节点状态数据是调度器调度的重要数据,因此这部分数据一定不能随意更改。
Pod的创建、删除、同步流程都在 syncLoop 的循环中进行,这也是我们会看到 Kubelet 的循环状态管理比较复杂的部分,就类似一个异步的IO Select模式。
Kubelet启动 Run方法进入主循环,syncLoop 继续调用真实的 syncLoopIteration; 这里有个错误处理,就是如果一次 syncLoopIteration 失败,还会继续重复,在重复执行以前,也会检查 runtime(主要是容器运行时和网络) 的异常,如果已经知道有异常,就sleep后再进行重试;
syncLoopIteration 就是上面的图提到的监听循环框架的内的主要监听逻辑,主要监听上述的5个channel,分别对应不同的handlePod事件处理函数。
Pod的各种事件其实是分发给了事件处理器PodWorker处理,事件处理函数在整个循环内必须是非阻塞的,否则会阻塞主要的管理协程,因此这里处理Pod状态变化事件是交给podWorkers启动的worker协程异步处理;另外,podWorker调用的pod的相关的处理函数也得是幂等的,否则上层的失败重试可能导致数据不一致。
podWorkers 位于 pkg/kubelet/pod_workers.go 主要是用于接收 Pod 更新,并判断是否启动新 worker 处理Pod;
每一个worker协程执行如下循环,不断的从 UpdatePodOptions channel 中获取Pod的更新,处理相关更新,也就是做Pod的状态同步,这里回调了 p.syncPodFn 函数,这个函数是在kubelet中赋值初始化的:
klet.podWorkers = newPodWorkers(klet.syncPod, kubeDeps.Recorder, klet.workQueue, klet.resyncInterval, backOffPeriod, klet.podCache)
这个syncPod的逻辑比较庞大,位于 pkg/kubelet/kubelet.go中, 做了很多工作,注意他只是针对单个Pod的状态同步逻辑。这里我不会贴代码,细节大家可以自行搜索代码进行阅读,硬骨头还得自己啃!
主要概括该函数做的工作:
- 首先判断是否是收到的是直接杀 Pod的更新事件,如果是,更新 status manager 中pod状态,并直接发送 kill 信号,退出循环
- 如果Pod 正在被创建或者是其他同步,调用 generateAPIPodStatus 生成一个 v1.PodStatus 对象;
- 将 status 对象更新到 status manager
- 杀掉不应该运行的pod,需要符合下面条件:
- 不被kubelet认可(如标签不符合、超过pod-limit等)
- 标记为删除状态(设置了优雅退出时间)
- 状态为failed的pod
- 确保Pod的cgroup的创建,这个是一个开关,可控
- 为Pod准备本地数据目录资源,如果目录不存在则新建,这些资源目录主要包括 pod目录,volume 目录,plugin 目录
- 等待卷挂载,注意这里是同步阻塞的,如果挂载失败,就直接退出,因为启动容器的前提必须是所有卷挂载成功
- 获取拉取镜像需要的 secrets
- 调用容器运行时进一步操作Pod内部的容器相关资源,可能是启动容器,杀死容器等;
上述任何步骤出错,都是直接跳出循环的,等待下一次重试;
从上述的主体流程可以看到,不管是创建、删除、更新Pod,其实都走的是同样的循环状态更新,所以这里最终操作,需要syncPod 自行判断该做什么,其实是比较复杂的;
这个复杂的过程,一个在于 Kubelet 自己需要监控 Pod 的真实状态,这个主要从上述数据流图中的 statusManager、livenessManager、Pleg 中获取真实的容器事件或者状态,而除此之外,Kubelet需要从 APIServer获取数据唯一的可信源,也就是声明式API的 Desired State Of World (下文简称 dsw); 通过 对比 Actual State Of World (下文简称 asw) 做出相关决策;
所以,下文讲述两个流程,不再给出源码,因为源码有非常多的细节和代码量,我们只抽象一些重要步骤和关键细节;
Pod 的创建流程
下面是我之前工作的时候通过压测统计出来的一些Pod创建时序数据,可以大致看到Kubelet创建Pod主要的时间分布。


创建过程并不是非常复杂,整个逻辑就是上文提到的syncPod这个流程当中。
Pod 的删除流程
Pod 的删除流程比创建流程要复杂一些,也是排查问题最多的点,经常可能会出现各种数据不一致,比如无法删除,或者Etcd里的元数据没了,但是其实这个Pod的容器还重启,这里的关键在于删除涉及到资源的清理,是一个异步的过程;
如果不是force模式去强制删除Pod,Kubernetes的对象都有一个deleteTimestamp, 也就是说删除并不是一次性完成的,而是先更新对象,标记其处于删除状态,最后Kubelet其实是把删除当做两次更新来操作的,最终是Kubelet完成的Pod对象数据的真实删除。有时候用户虽然从控制面的元数据层强制删除了Pod,但是实际上Kubelet节点上的Pod因为某种原因,并没有删除成功,导致磁盘等资源残留。
Kubelet并发性能压测数据
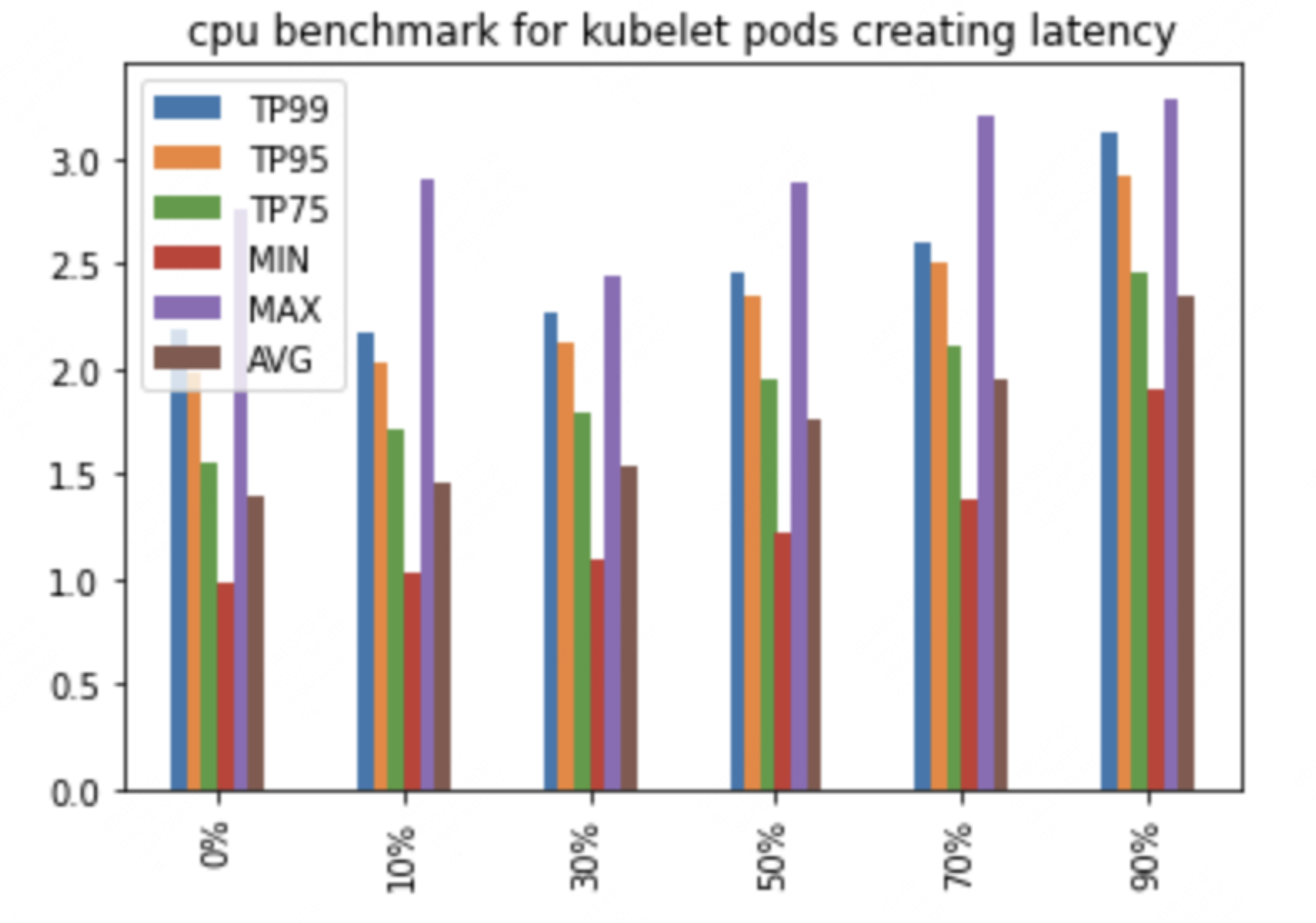
通过测试CPU和IO对并发创建Pod在Kubelet耗时影响,来分析Kubelet受影响的主要因素。
横坐标是压测Kubelet所在节点的CPU负载占比,纵坐标表示并发创建32个Pod耗时分位数和均值(镜像已经提前下载),可以看到,只要Kubelet还能抢到cpu,其实cpu负载对Kubelet影响不大
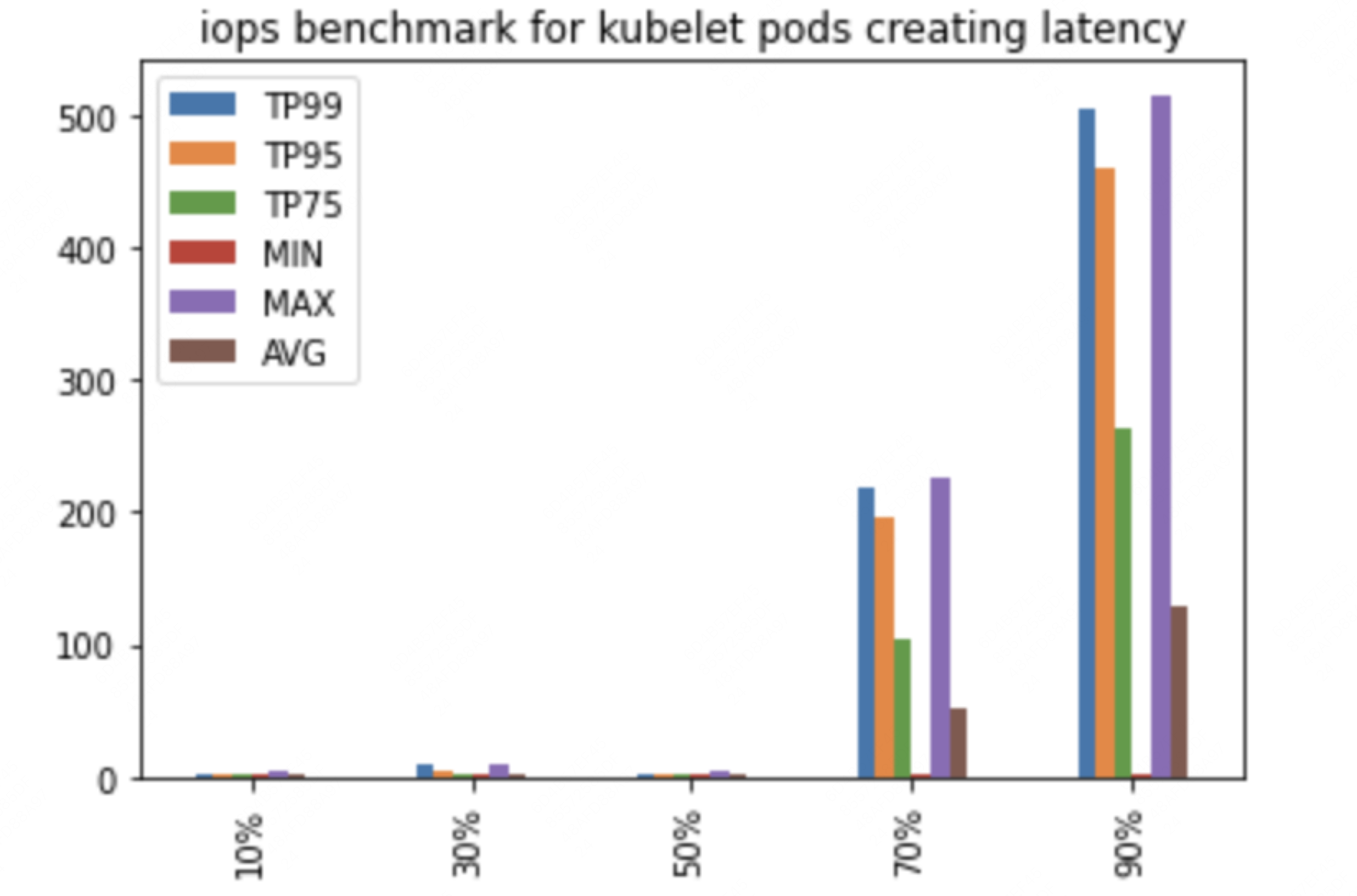
横坐标表示压测kubelet所在节点的IO占宿主机的IO百分比,纵坐标表示并发创建32个Pod耗时分位数和均值(镜像已经提前下载),可以看到Pod的创建时延收到IO影响是非常明显的,宿主机IO负载超过50%以上以后,时延就开始飙升。
CRI/CNI/CSI
这是K8S对接计算、网络、存储的三大协议规范,这里不做详细说明,后续会给出具体每种接口规范的分析。
CRI/CNI
CRI 就是Kubernetes负责对接的容器运行时,比如最开始的时候Kubernetes主要使用的是Docker,后来Docker废弃,主要的运行时就是Containerd。
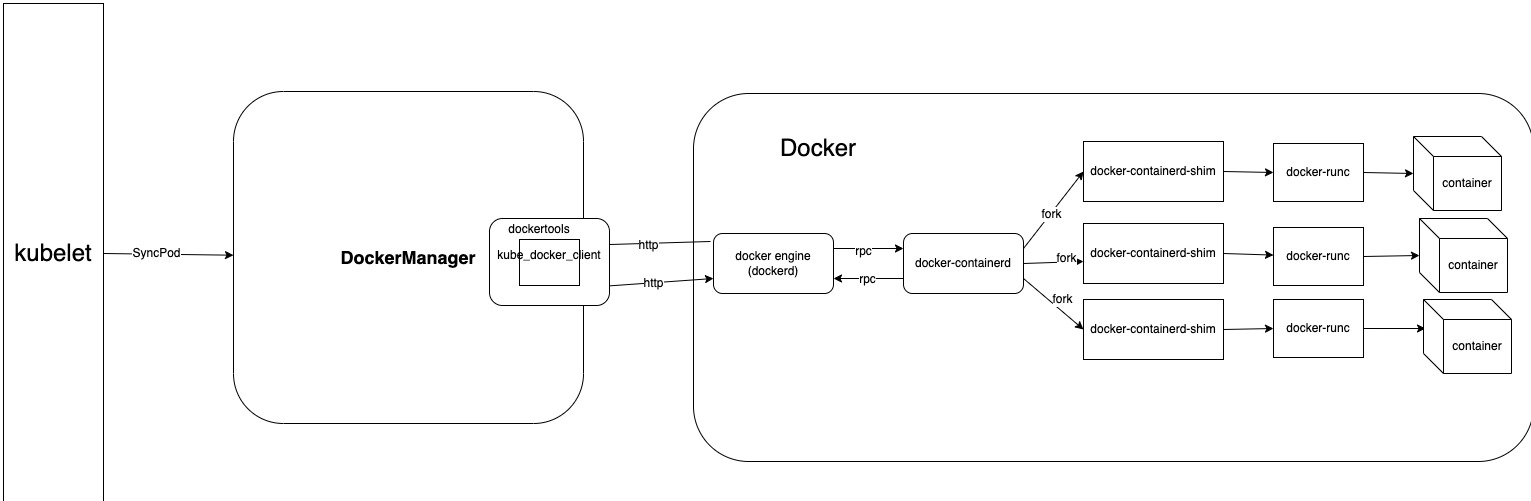 这是Kubernetes的MVP版本的运行时,其实最初直接对接了Docker来运行容器。
这是Kubernetes的MVP版本的运行时,其实最初直接对接了Docker来运行容器。
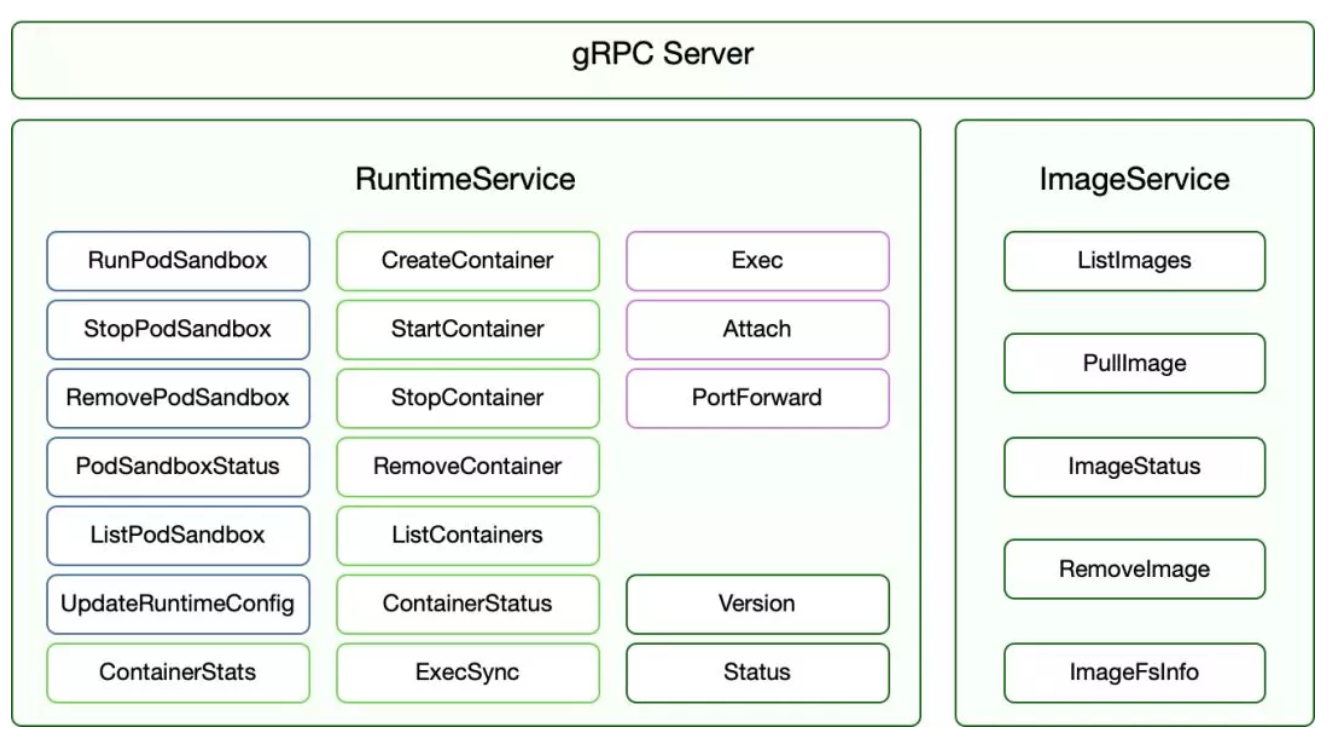
后来社区提出了CRI规范,然后这个接口就被抽象成了一组规范,并使用gRPC作为接口调用协议。
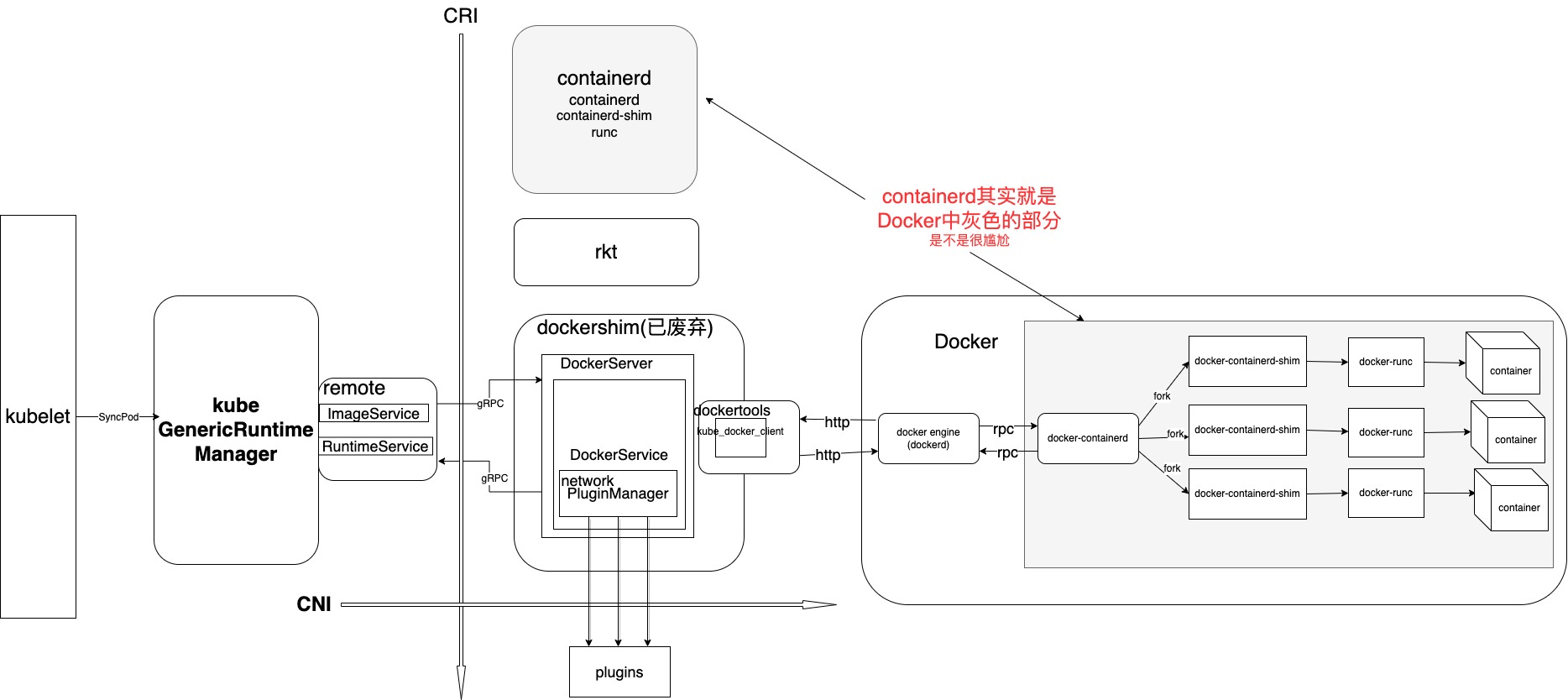
 随着演进,出现了Dockershim和RKT以及Containerd,其实Dockershim本身就比较冗余,所以被取代也是必然。社区在Kubernetes 1.24版本中正式将dockershim 组件从 kubelet 中删除。
随着演进,出现了Dockershim和RKT以及Containerd,其实Dockershim本身就比较冗余,所以被取代也是必然。社区在Kubernetes 1.24版本中正式将dockershim 组件从 kubelet 中删除。
CSI
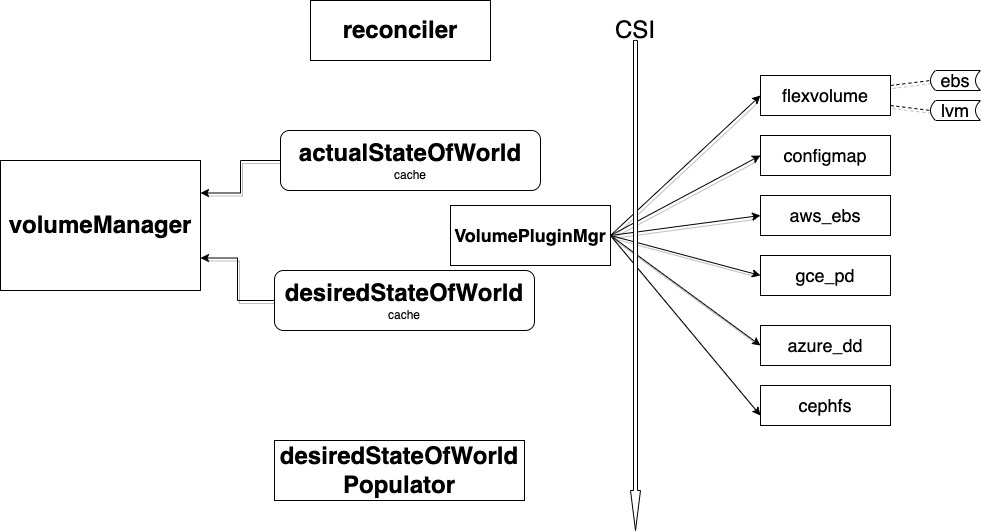
CSI是存储卷管理的重要部分,该部分也比较复杂,笔者以后会专门写文章来分析该模块。
总结
- kubelet 主要采用异步IO的循环模式,主框架协程会监听各种渠道的事件,然后分发给podWorkers处理,并通过和CRI、CNI、CSI的对接实现Pod的增删改查,最后将节点和Pod状态更新到APIServer。
- kubelet 对IO是比较敏感的,所以排查问题切记关注下会影响IO的组件:
- 包括pleg的relist也会产生IO开销,导致Pod创建延迟升高或者阻塞的原因,很多时候和这里也相关,这里主要原因还是在于不停的list对于 CRI 来说有含有对文件系统的操作,此时容器运行时有比较大的开销进而导致阻塞,社区也提到过基于流式的事件通知机制的pleg,但是还未实现,另外就是优化CRI运行时本身某些操作可能开销较大的逻辑。
- 镜像下载和解压,这里一个是下载镜像会产生IO,另一个是解压产生CPU消耗,如果镜像非常大,并发启动的Pod多的时候,此时也会影响Pod的创建,所以优化镜像大小和解压时间也是一个重要方向,目前业界也有很多工作,包括镜像预分发、镜像加速、存储分层优化等技术。
kubelet 是一个复杂的异步事件驱动的系统,由于基础设施CNI、CSI、CRI的复杂性,Pod的状态可能并不会很快和DesiredStateOfWorld一致,它必须通过最终一致性来实现,如果是强一致性,通过命令式API创建Pod后必须是一次请求,请求必须成功或者失败后需要各种处理,那么此时所有的后续处理都交给了上层也就是应用层,声明式其实就是将复杂度交给底层,由Kubernetes来完成这种复杂性处理。
思考
我们理解了Kubelet的主要实现框架和数据流程,那么如果要实现一个 Virtual Kubelet的话,该如何实现呢?目前Virtual Kubelet大致分两类:
第一种是用来做模拟和压测的,比如在大规模集群控制面压力测试或者资源调度模拟的时候,我们并不会启动真实的节点去运行Kubelet,也不需要真实的把Pod运行起来,而是采用伪装和模拟的方法,在一个进程或者容器内启动上百甚至上千个Kubelet去连接APIServer,但是消耗非常少的真实资源,比如几个容器就可以模拟出上万个Kubelet节点,并能够模拟出负载等相关指标数据。
第二种类型是需要承载真实的Pod的,但是它并不是一个真实跑在宿主机上的Kubelet进程,而是虚拟出来的抽象的节点服务,企业如果想在原来的Kubernetes集群扩容云上弹性容器实例,则可以采用Virtual Kubelet的模式,将Virtual Kubelet 对接到公有云,实现云原生的Pod弹性扩缩容,按量计费,免去运维节点和复杂Kubelet的运维成本。比如弹性容器实例(比如腾讯云的EKS Pod)是目前云厂商普遍提供的一种兼容标准Kubernetes控制面的服务,都是虚拟节点,无需进行节点运维。